Ubuntu 21.10 已经默认 部分 安装了 PipeWire 并用于 WebRTC。我们只需要安装 PipeWire 所需的蓝牙音频编码器,并替代默认的 PulseAudio 声音系统即可自动启用 LDAC / AAC / AptX 支持。
在 VMware Workstation 桥接模式的网卡上让虚拟机使用 VLAN 的正确方法
要解决的问题
有一个虚拟机运行在 VMWare workstation 中,如何让这个虚拟机桥接到宿主机的网络上的某个 VLAN?
常见使用场景
只有一个网口的单臂软路由,同时宿主机为 Windows,虚拟机软件为 VMware Workstation,在虚拟机中运行 OpenWrt
需要在一个网口上,利用 VLAN 实现虚拟 WAN 口上的 PPPoE 拨号和 虚拟 LAN 口上的上网服务。
方法
- 根据宿主机网卡的品牌,下载对应的 VLAN 设置软件。已知 Realtek 和 Intel 网卡都提供这样的软件。Realtek 网卡的软件为 Realtek Ethernet Diagnostic Utility
- 下文以 Realtek 网卡为例。如果你的网卡厂商不提供 VLAN 设置软件,请直接转到文末
- 在宿主机上设置你想要使用的 VLAN 编号,软件将会创建一个虚拟网卡。记住网卡名称和适配器名称
在 Windows 上设置 NAT 或网络共享的正确方法——避免Wi-Fi热点无法使用
最近在我的笔记本上用 WireGuardServerForWindows 项目搭了一个 WireGuard 服务端,但是发现一个问题,我一给 WireGuard 开网络共享,我就没法开 Wi-Fi 热点了
罪魁祸首:SharedAccess
目前的NAT的普遍做法是用 SharedAccess 服务,也就是你在控制面板看到的那个 “Internet 连接共享”
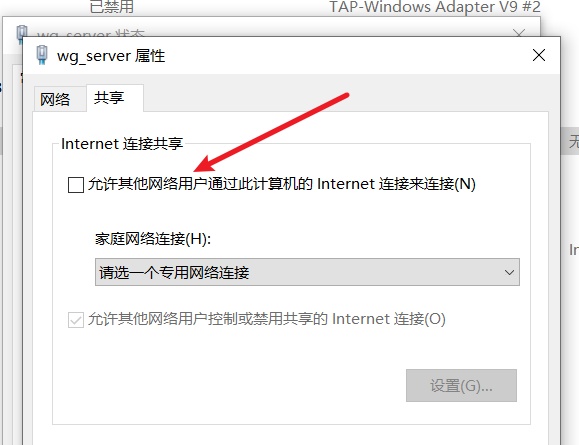
但是这个服务是针对热点的设计的,只能支持一个 NAT 实例,这意味着,由于SharedAccess服务已经被wireguard服务器的NAT占用掉了,你就没办法建立一个有 Internet 的 Wi-Fi热点
但是,如果,使用New-NetNat命令,就能够设置许多NAT实例,同时可以用热点。
方法
自编译 红米 AC2100 OpenWRT R21.7.26
分享一下之前自行编译的路由器固件给有需要的人
一句话总结特点:锐捷 | 闭源驱动 | Wireguard | 组网 | NFS | 多拨 | 弱信号剔除
Linux 内核结构和子系统简介
本文是对 Anatomy of the Linux kernel 的部分翻译。
操作系统是计算机技术不可或缺的组成部分,是硬件设备在应用领域的延展与扩充,能够有效规划和设计计算机的工作流程,保证资源的合理配置和科学管理,确保用户能够便捷自如地操作计算机,满足多层面的任务需要。[1]在计算机上配置操作系统,主要是为了方便用户使用;提高系统资源利用率、提高系统吞吐量;方便增添新的功能和模块;遵循世界标准规范。一个没有配置操作系统的计算机几乎是无法使用的。
自计算机产生以来,人们就开始关注操作系统的研究。本文将就目前在移动端、桌面端、服务器使用较为广泛的操作系统内核Linux展开论述。
Linux 内核简介
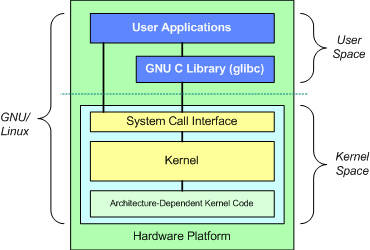
图 1 Linux 基本体系结构
如图所示。用户和应用程序空间位于顶部。此处执行用户应用程序。用户空间下面是内核空间。Linux内核运行在此处。
另有GNU C库(glibc)。它提供连接到内核的系统调用接口(System call
interface),并提供了在用户空间(user-space)的应用程序和内核之间转换的功能。因为内核和用户应用程序占用不同的受保护地址空间。并且,尽管每个用户空间进程都占用其自己的虚拟地址空间,但内核仅占用一个地址空间。[2]
Linux内核可以进一步分为三个级别。顶部是系统调用接口,该接口实现诸如读取和写入之类的基本功能。在系统调用接口下方的是内核代码,是与体系结构无关的内核代码。该代码是Linux支持的所有处理器体系结构的通用代码。在此之下是与体系结构相关的代码,该代码通常称为BSP(Board
Support Package,
板级支持包)。该代码用作特定体系结构的处理器和特定平台的代码。
Linux内核分为许多不同的子系统。
Linux也可以看作是一个整体,因为它将所有基本服务集中到内核中(宏内核)。这与微内核体系结构不同,在微体系结构中,内核提供基本服务,例如通信,I/O,内存和进程管理,而更具体的服务则进入微内核层。
随着Linux的发展,Linux内核在内存和CPU使用率方面日渐高效,并且非常稳定。Linux最值得称道的方面是它的可移植性。可以将Linux编译为可在具有不同体系结构约束和需求的大量处理器和平台上运行。例如,许多家用路由器(例如小米、华硕、斐讯)都运行基于Linux的OpenWRT的厂商定制版。
Linux 主要子系统
操作系统的主要功能包括处理机管理、存储器管理、设备管理、文件管理、用户接口。处理机管理包括进程控制、进程同步、进程通信、调度。存储器管理包括内存分配、内存保护、地址映射、内存扩充。设备管理包括缓冲管理、设备分配、设备处理。文件管理:文件存储空间管理、目录管理、文件的读写管理和保护。用户接口包括联机用户接口、脱机用户接口、图形用户接口。[3]这正是Linux的主要子系统。
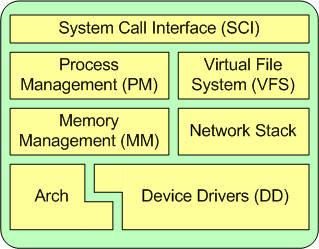
图 2 Linux的主要子系统
处理机管理: Linux 进程调度
进程(Process)调度负责进程的执行和管理。在内核中,这些进程称为”线程”,代表对处理器的一个虚拟化(virtualization)。。在用户空间中,虽然Linux并未将两个概念(进程和线程)分开,但我们仍然通常使用术语”进程(Process)”。内核通过SCI提供了一个应用程序接口(API)来创建新进程(fork,exec或其他
POSIX
函数),停止进程(强制结束(kill),退出(exit))以及在它们之间进行通信和同步(信号(signal)或其他POSIX机制)。此API通常被init程序(现在通常为systemd)调用来创建新进程。
在进程管理中,还需要在活动线程之间共享CPU。Linux内核实现了一种新颖的调度算法,该算法可在常数时间执行,而与争用CPU的线程数量无关。称为O(1)调度程序(O(1)
scheduler),表示调度一个线程和调度多个线程所花费的时间相同。O(1)调度程序还支持多个处理器(称为SMP(对称多处理))。
存储器管理: Linux 内存管理
内核管理的另一个重要事项是内存。为了提高效率,考虑到硬件管理虚拟内存的方式,内存以”页面”(对于大多数CPU体系结构,页大小为4KB)进行管理。
Linux存储器管理包括管理可用内存的方法,以及用于物理和虚拟内存映射的硬件机制。
但是内存管理不仅仅是管理4KB缓冲区。Linux还提供了4KB缓冲区(例如slab分配器)上的抽象。该内存管理方案使用4KB缓冲区作为基础,然后从内部分配结构,跟踪哪些页已满、哪些只使用了一部分、哪些为空。该方案能够根据更大系统的需求动态增长和收缩。
Linux支持多个内存”用户”,物理内存经常会耗尽。为了解决此问题,可以将页面移出内存并移至磁盘上。此过程称为交换(swapping),因为页面是从内存交换到硬盘上的。
文件管理: 虚拟文件系统(VFS)
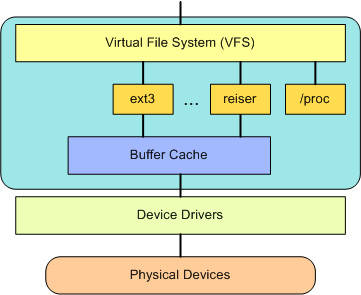
图 3 VFS
虚拟文件系统(VFS)为文件系统提供了通用的接口抽象。
VFS在SCI和内核支持的文件系统之间提供了一个交换层(图3)。
VFS的顶部是通用的API的抽象,例如打开,关闭,读取和写入。
VFS的底部是文件系统的抽象,定义了如何实现上层功能。这些是给定文件系统的插件(内核有50个以上)。
文件系统层下面是缓冲区高速缓存,它为文件系统层提供了一组通用功能(独立于任何特定文件系统)。该缓存层通过将数据保留很短的时间(或预先推测性读取,以便在需要时可以使用数据)来优化对物理设备的访问。缓冲区高速缓存下方是设备驱动程序,这些驱动程序实现了特定物理设备的接口。
用户接口: 系统调用接口(SCI)
SCI是一个相当简单的”层”,提供了从用户空间到内核执行函数调用的方法。如前所述,即使在同一系列的处理器中,此接口也可能依赖于CPU体系结构。
SCI实际上是一种调用复用和解复用服务。
系统调用接口是为函数调用服务是一种特殊机制,主要完成从客户到内核数据的调用,并将源码储存起来。客户能够对进程进行控制,主要运用调用接口来实现,在各进程中能够完成实时通信。通信机制有多种,常使用的如signal等。
Linux 网络栈
Linux网络栈遵循根据协议本身建模的分层体系结构,例如OSI模型。在Linux网络栈中,IP协议仍是位于传输层(如TCP)之下的核心网络层协议。TCP之上是套接字(Socket)层,它是通过SCI调用的。
套接字(Socket)层是网络子系统的标准API,并为各种网络协议提供用户界面。包括原始IP协议数据单元(PDU)、TCP、UDP,套接字层提供了一套标准方法来管理连接并在端口之间传输数据。
Java 快速读取文本 (算法竞赛适用)
背景: 远离 Scanner
今天无意翻阅 Scanner 类时,发现了一个很坑的地方:
// 摘抄自 Scanner JDK15 源码
public final class Scanner implements Iterator<String>, Closeable {
....
// Internal matcher used for finding delimiters
private Matcher matcher;
// Pattern used to delimit tokens
private Pattern delimPattern;
// Pattern found in last hasNext operation
private Pattern hasNextPattern;
private Pattern integerPattern;
private String digits = "0123456789abcdefghijklmnopqrstuvwxyz";
private String non0Digit = "[\\p{javaDigit}&&[^0]]";
private int SIMPLE_GROUP_INDEX = 5;
private String buildIntegerPatternString() {
String radixDigits = digits.substring(0, radix);
// \\p{javaDigit} is not guaranteed to be appropriate
// here but what can we do? The final authority will be
// whatever parse method is invoked, so ultimately the
// Scanner will do the right thing
String digit = "((?i)["+radixDigits+"\\p{javaDigit}])";
String groupedNumeral = "("+non0Digit+digit+"?"+digit+"?("+
groupSeparator+digit+digit+digit+")+)";
// digit++ is the possessive form which is necessary for reducing
// backtracking that would otherwise cause unacceptable performance
String numeral = "(("+ digit+"++)|"+groupedNumeral+")";
String javaStyleInteger = "([-+]?(" + numeral + "))";
String negativeInteger = negativePrefix + numeral + negativeSuffix;
String positiveInteger = positivePrefix + numeral + positiveSuffix;
return "("+ javaStyleInteger + ")|(" +
positiveInteger + ")|(" +
negativeInteger + ")";
}
private Pattern integerPattern() {
if (integerPattern == null) {
integerPattern = patternCache.forName(buildIntegerPatternString());
}
return integerPattern;
}
public int nextInt(int radix) {
// Check cached result
if ((typeCache != null) && (typeCache instanceof Integer)
&& this.radix == radix) {
int val = ((Integer)typeCache).intValue();
useTypeCache();
return val;
}
setRadix(radix);
clearCaches();
// Search for next int
try {
String s = next(integerPattern());
if (matcher.group(SIMPLE_GROUP_INDEX) == null)
s = processIntegerToken(s);
return Integer.parseInt(s, radix);
} catch (NumberFormatException nfe) {
position = matcher.start(); // don't skip bad token
throw new InputMismatchException(nfe.getMessage());
}
}
....
}
可见,Java 的 Scanner 是基于正则表达式实现的,这意味着 Scanner 的效率 相当低。如果在蓝桥杯之类的算法竞赛用 Scanner,会有很大一部分CPU时间会浪费在 Scanner 的正则解析上,就很可能跑出 TLE

这篇文章不探讨如何快速读取大型一般二进制文件,关注重点在于在低 JDK 版本下,如何快速解析文本,而非 “快速“ 读取文件。快速读取一般二进制大文件请考虑:
- 读取缓冲:使用直接缓冲 ByteBuffer.allocateDirect()
- 内存映射文件 FileChannel + MappedByteBuffer
认识 StringTokenizer
StringTokenizer 是一个自 Java 1.0 就被引入的类,用于以标识符分隔字符串,也就是解析文本
Scanner 之所以复杂,主要在于它假定所有输入数据都是任意的、类型是不确定的,同时 Scanner 还要兼顾处理输入流,所以不得不使用正则表达式去进行处理。
由于算法竞赛的给定数据的类型都是已知的,我们可以直接使用 StringTokenizer 去代替 Scanner
有报告显示,StringTokenizer 结合 BufferedReader 读入流的性能甚至高于 C 语言的 scanf()
构造方法
StringTokenizer 有三个常用构造方法
- 直接输入要解析的字符串,默认会把 “ \t\n\r\f” 当作分隔符。同时,解析返回结果不包含分隔符
Constructs a string tokenizer for the specified string. The tokenizer uses the default delimiter set, which is “ \t\n\r\f”: the space character, the tab character, the newline character, the carriage-return character, and the form-feed character. Delimiter characters themselves will not be treated as tokens.
Params: str – a string to be parsed.
Throws: NullPointerException – if str is null
public StringTokenizer(String str) {
this(str, " \t\n\r\f", false);
}
- 输入要解析的字符串和分隔符列表。解析返回结果不包含分隔符
Constructs a string tokenizer for the specified string. The characters in the delim argument are the delimiters for separating tokens. Delimiter characters themselves will not be treated as tokens.
Note that if delim is null, this constructor does not throw an exception. However, trying to invoke other methods on the resulting StringTokenizer may result in a NullPointerException.
Params: str – a string to be parsed.
delim – the delimiters.
Throws: NullPointerException – if str is null
public StringTokenizer(String str, String delim) {
this(str, delim, false);
}
- 输入要解析的字符串和分隔符列表。你决定要不要包含分隔符,true 为包含。
用法
获取每一段字符串 nextToken()
public String nextToken()
返回每一段被分隔的字符串 (token),等效于 Scanner.next(), 返回结果是否包含分隔符取决于你的构造参数
如果没有更多 token,会抛出 java.util.NoSuchElementException
看看还有没有更多待分隔的字符串 hasMoreTokens()
public boolean hasMoreTokens()
true 表示有更多,可以安全地调用 nextToken()
增强 StringTokenizer
问题来了,StringTokenizer 好像并没有 Scanner 的 nextInt() nextLong() 之类的东西,怎么办?
现场写个类去解析他!
import java.util.StringTokenizer;
public class ExtendedStringTokenizer extends StringTokenizer {
public ExtendedStringTokenizer(String str) {
super(str);
}
public long nextLong() {
return Long.parseLong(this.nextToken());
}
public double nextDouble() {
return Double.parseDouble(this.nextToken());
}
public int nextInt() {
return Integer.parseInt(nextToken());
}
}
只需继承一下 StringTokenizer,寥寥几行代码便可搞定
注意:此处 nextInt() nextLong() 不允许输入为小数,否则会引发解析错误。如果确实需要处理小数,可以考虑在解析前使用 indexOf() 和 substring() 截去小数。
文件,以及有 EOF 的流快读方案
现在知道如何解析字符串了,但是怎么从流中读入字符串呢?
假设现在我们有了一个 InputStream inputStream,这个 InputStream 可以是:
- 标准输入
System.in - 文件
FileInputStream("FileName")
由于算法竞赛的 JDK 版本一般很低,无法使用 NIO
一次性全部读入
这是性能最好的,并且是典型的空间换时间的方案。
以蓝桥杯竞赛为例,通常提供高达 512 MB 的算法运行内存空间,这个时候可以直接把整个流全部读入后解析。
DataInputStream stream = new DataInputStream(inputStream);
ExtendedStringTokenizer tokenizer = new ExtendedStringTokenizer(new String(stream.readAllBytes()));
注: Java 1.7 以上可以使用 Files.readString(Path.of("filename")) 直接读入整个文件到字符串
为什么不直接使用 DataInputStream
有读者可能注意到了这里并没有直接使用 DataInputStream 提供的 readInt() readDouble() 等方法,这里有一点需要理解:
例如,下面代码:
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream("5 1234567 2".getBytes());
DataInputStream dataInputStream = new DataInputStream(byteArrayInputStream);
System.out.println(dataInputStream.readLong());
System.out.println(dataInputStream.readLong());
System.out.println(dataInputStream.readLong());
输出:
3828113774942106934
Exception in thread "main" java.io.EOFException
根本不是我们想要的。
上面的说法是为了告诉你不要用它,事实上,更准确的说,readInt() readDouble() 是把一串二进制字节当作一个整体读入,用于处理二进制文件。与我们今天要做的事情(读取文本)一点关系都没有。
逐行读入
Reader 是专用于处理字符流的类,相对的,Stream 处理的是字节流
逐行读入时,使用 BufferedReader 包装 InputStreamReader, InputStreamReader 包装 InputStream 可以有效提升性能
// 注:BufferedReader 可以提供第二个参数,类型为 int,表示缓冲区容量,提供一个较大的容量可以更快
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
ExtendedStringTokenizer tokenizer = new ExtendedStringTokenizer(line);
// TODO: your code
}
如果读取目标是文件,可以用 new FileReader("filename") 代替 new InputStreamReader(inputStream)
由于 StringTokenizer 只是一个简单的小对象,所以循环反复创建的开销还是很小的。但还是比一次性读入慢了很多
不提供 EOF 的无限流快速方案
注意:
System.in标准输入流不一定不提供 EOF,若用户在终端上按下Ctrl+D或通过其他方式输入等效内容,则System.in会将此视作一个 EOF。但若用户一直不按Ctrl+D那就是无限等待输入了。
由于这种流不提供 EOF,我们没法直接全部读入,直接全部读入会造成永久阻塞。
但是,这种流肯定会告诉我们输入数据有多少行,我们可以用行数作为依据判断是否还要继续读。
假设第一行告诉我们后续输入有多少行:
// 注:BufferedReader 可以提供第二个参数,类型为 int,表示缓冲区容量,提供一个较大的容量可以更快
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
ExtendedStringTokenizer initTokenizer = new ExtendedStringTokenizer(reader.readLine());
int lineNum = initTokenizer.nextInt();
for (int i = 0; i < lineNum; i++) {
// TODO: your code
ExtendedStringTokenizer tokenizer = new ExtendedStringTokenizer(reader.readLine());
}
如果读取目标是文件,可以用 new FileReader("filename") 代替 new InputStreamReader(inputStream)
Reader 逐字符读取
如果输入数据,一个字符(注意不是字节)就是一个整体,那么还可以逐字符读取:
所用方法:
public int read()
读一个字符,并返回它。如果读到了 EOF 则返回 -1
例如:读取一个 ASCII 编码的、读取目标为数字、有换行符的文件到一个二维数组,每一个数字都是一个整体,每次换行就读取到数组的下一行。
var reader = new BufferedReader(new FileReader(PATH), 1 << 16);
byte[][] maze = new byte[100][100]; //读取的结果位于 0~9 之间,byte省空间
int lineCode = 0; // 也是实际有效行数
int colCode = 0; // 实际有效列数
int token;
while ((token = reader.read()) != -1) {
if (token >= '0' && token <= '9') {
maze[lineCode][colCode] = (byte) (token - '0');
colCode++;
} else if (token == '\n') {
lineCode++;
if (colCode == 0) {
colNum = colCode;
}
colCode = 0;
}
}
多个数字(字符)是一个整体
对于多个数字是一个整体的,当然也可以使用自行读取一组数据到缓冲区,然后自行解析。然而,编写解析代码所花费的时间可能远不如使用 StringTokenizer 划算,而且这样操作带来的性能提升实际上也非常有限。
所用 Reader 方法:
public int read()
public int read(char cbuf[], int off, int len) throws IOException
后者为:从流中读取指定长度(len)的字符流,并从偏移量(off)开始装入你的数组 cbuf[],返回实际读取的有效长度(实际长度小于等于 len)
当然也可以使用前文提到的 DataInputStream
后记:一些常见误区
遍历字符串,不要 toCharArray() 后遍历
就我个人在 LeetCode 的刷题经验,当字符串编码为 Latin 时,直接 String.charAt() 会比 toCharArray() 后遍历更快(事实上在 JDK 源代码也可以找到相关依据)。
若对此有疑问,请阅读 toCharArray() 的源代码,并与 String.charAt() 进行对比,可见:
toCharArray()会创建一个新字符数组,然后逐字符拷贝,并与0xFF进行与运算,这比System.arraycopy()直接数组拷贝的性能低很多。- 尽管
charAt()也会进行一次与运算,但却不需要逐字拷贝而是直接访问 String 内部的字符数组。
利用 ThreadLocal + Lambda,实现有状态变量的单例模式
通常情况下单例模式的对象不应该具有状态,然而现实是复杂的,总会有那么一些特殊情况下需要小小地【违例】一下。
动机
一个父类的方法执行前需要设置一个变量的值,变量值会对方法的执行结果产生影响。现希望子类以单例的方式继承父类。
以我实际遇到的一个问题为例,JOOQ 是一个 ORM 类库,这个类库能够自动扫描数据库并生成 DAO,但是自动生成的 DAO 功能有限,通常需要继承来扩展这些 DAO。每个 DAO 在实例化时需要传入一个 Configuration,这个 Configuration 包含有关数据库的信息。
通常情况下 Configuration 可以由所有的 DAO 共享,然而,在启动事务后 Configuration 会被 JOOQ 派生,且后续所有的事务内数据库操作都应该使用派生的 Configuration。
现希望子 DAO 为单例,同时,在不改变父 DAO 的情况下,且不修改子 DAO 的已有方法和对这些方法的调用的情况下,实现 configuration 变量的 “智能” 修改。
我们可以利用 ThreadLocal + Lambda 解决这个问题。
基本概念
ThreadLocal
ThreadLocal<E> 是一个容器,它内部采用 Map 实现,以线程的某种唯一特征为键,用户自定义类型 E 为值。因此不同线程存取同一个 ThreadLocal 容器会得到不同的值,且不同线程互不影响。一个线程总是只能访问到属于他自己的那份值。
Kotlin 协程
建议先跳过本节
Kotlin 协程除了具有协程的本身本性之外,实际上是由 Kotlin 管理的一个线程池。
协程的挂起指的是当前正在运行一块协程代码的线程从这块代码脱离,不再负责这块代码的执行。线程暂时处于空闲状态。每当执行到一个 suspend 函数调用时,都会发生挂起。
协程挂起发生后,开始执行 suspend 函数,负责具体执行这个函数的线程由函数的 withContext() 调用决定。注意:此时可能发生了线程的切换,脱离了原先的线程。
suspend 函数完成后,刚才挂起的协程代码恢复执行。注意:此时可能再次发生线程切换,刚才没执行的代码继续回到原先的线程执行。
问题的解决
要解决一开始提出的问题,容易想到,我们可以利用 ThreadLocal 声明一个“全局”变量,当 DAO 需要用到 Configuration 时,就从 ThreadLocal 容器去取。
同时,再声明一个函数,负责临时更改 ThreadLocal 容器的 Configuration 具体值,当传入的 lambda 执行完毕后再改回原先状态。
传入的 lambda,就是我们希望在新的 Configuration 上下文中所执行的代码。
fun <R> Configuration.use(then: ((Configuration) -> R)): R {
//jooqConfigurationOrNull 是负责管理存储 Configuration 的属性
val initialState = jooqConfigurationOrNull //保存初始状态
jooqConfigurationOrNull = this //临时变更为新状态
return try { //注意捕获异常,防止发生异常时无法还原状态
then(this) //执行传入的 lambda 代码块
} catch (exception: Throwable) {
logger.debug("Config use block failed: $exception")
throw exception //原样抛出异常
} finally {
logger.debug("Recover thread local jooq config to initial")
jooqConfigurationOrNull = initialState //还原初始状态
}
}
var currentThreadJooqConfiguration: Configuration
get() = currentThreadJooqConfigurationOrNull ?: jooqConfiguration
set(value) { currentThreadJooqConfigurationOrNull = value }
//合理利用 getter 和 setter 让 ThreadLocal 对用户不可见
var jooqConfigurationOrNull: Configuration?
get() = currentThreadJooqConfigurationContainer.get()
set(value) {
if (value == null)
currentThreadJooqConfigurationContainer.remove()
else
currentThreadJooqConfigurationContainer.set(value)
}
// 真正的全局 ThreadLocal 容器
private val currentThreadJooqConfigurationContainer = ThreadLocal<Configuration>()
val jooqConfiguration: Configuration
get() = realJooqConfiguration.derive() // derive() 等效 clone(),直接取的总是派生出来的。
private lateinit var realJooqConfiguration: Configuration // 派生的根基。只做派生用途。
由于使用了 ThreadLocal,不同线程从该容器取出的结果各不相同且不会互相影响。同时,由于我们的代码霸占着这个线程,因此这里虽然临时改变了 jooqConfigurationOrNull ,但是对其他线程并没有影响。
针对一开始提出的问题,要让父 DAO 获得的 Configuration 也发生改变,只需重写父类的 getter,让父类总是从 ThreadLocal 容器获得值即可。
局限
不难发现,刚才的做法实际上是有漏洞的。
- 如果 lambda 代码块内调用线程池执行其他代码,绝对不能执行和数据库操作相关的动作。这是容易理解的,我们所修改的
Configuration只在当前线程上下文起作用,调用线程池实际上就脱离了当前上下文。 - 不应该在 lambda 代码块内直接调用挂起函数。即使所调用的挂起函数并没有操作数据库也不可以。这是因为当前线程在空闲时可能会被安排执行其他协程任务,导致隐患。另外,当协程跑到其他线程上执行时上下文会丢失。
- (Kotlin) 不应该在 lambda 代码块内进行 return。若导致 use 函数没有执行后续还原初始状态的代码会导致大问题。
漏洞 1 可以通过人为规范避免。Kotlin 在语法上避免了 3 问题。
针对问题 2,要执行 suspend 函数比较困难,但是也不是不能做。首先,通过 runBlocking 使得当前线程处于阻塞状态,不允许安排其他协程任务(但遗憾的是你的函数也不肯在当前线程跑)。然后,使用 asContextElement 使协程上下文携带某种信息。但这意味着前面的代码几乎都得为此重写,总体上还是比较难做的。
状态压缩的动态规划问题:骨牌完全覆盖棋盘问题
这个算法问题对于算法菊苣们来讲不过是小菜一碟。发到博客主要是希望能够对未来拿到这个问题而毫无头绪的读者带来些许帮助。
这篇文章实际上是我的《算法分析与设计》课程的大作业,从 Word 粘贴到博客仅做了一些格式上的修改,因此文章风格会比较离谱(报告文档的风格),敬请谅解。
我的 Windows 10 2004 新增 Bug 解决办法记录
虚拟化相关
大量端口被无端保留,50000 以上高位端口无法分配
这是 Hyper-V 导致的,可以卸载 Hyper-V 平台解决它。
具体参考:
- Hyper-V和IDEA运行端口占用问题
- Cannot bind to some ports due to permission denied
- Unable to bind ports: Docker-for-Windows & Hyper-V excluding but not using important port ranges
系统为每个网卡都创建一个 vEthernet 虚拟网卡
这是 Hyper-V 平台导致的,只要装了 Hyper-V 平台就会这样,暂时没找到关闭办法。
先卸载 Hyper-V 平台、沙盒、容器、虚拟机平台、虚拟机监控程序平台。
如果之后需要使用这些功能可以重启后再启用。
WSL 2 进入 shell 卡死
执行:wsl --shutdown 强制停止 WSL 后再试。
VMware Workstation 兼容性问题
升级最新的 15.5.5 可以兼容 Hyper-V 了。
VMware Workstation 15 频繁未响应
似乎是一个 Bug,当剪贴板有图片时进入虚拟机就会导致卡死。
关于这个,我在 VMWare 社区发了个帖子:Workstation and Player GUI freezed when host clipboard has image on Windows 10
其他软件
手心输入法字体渲染模糊
打开手心输入法的安装目录,对所有的 exe:
属性 -- 兼容性选项 -- 更改所有用户的设置 -- 更改高 DPI 设置 -- 高 DPI 缩放替代 -- 选择 “应用程序”
另外可以禁用掉手心输入法的开机启动,没有任何其他影响
网易云音乐升级成了 x86 转制版本
我保留了一份 网易云音乐 UWP 版 Appx Bundle 存档,可以在这里下载:kenvix/NeteaseMusicUWP
这个沙雕版本正好和 Windows 10 2004 同时发布,就写到一起了
OneDrive 一直在 “连接中”
如果你开启了系统代理,请排除以下地址:
mobile.pipe.aria.microsoft.com
login.windows.net
此外,如果你使用 OneDrive for Business 还需要排除掉你的 SharePoint 域名,例如 example-my.sharepoint.com
解决 Android Studio 及 IDEA 中 Gradle 错误信息乱码的问题
错误现象
如图所示,在 IDEA 2019.X 以及 Android Studio 3.6.X, Gradle 在编译项目过程中所有中文错误提示均乱码。

Kotlin 的那些骚操作
最近在学习 Kotlin 这门编程语言,不得不感叹 Kotlin 这语言是真的骚。
重载操作符
在伴生对象重载 invoke 操作符
interface BotUser {
val id: Long
val name: String
val description: String
companion object {
operator fun invoke(
id: Long,
name: String = "",
description: String = ""
): BotUser {
return BotUserImpl(id, name, description)
}
}
}
class BotUserImpl(...) { ... }
如果你这样做的话,可以让接口或者抽象类仿佛看起来能够被实例化一样(看似调用“构造方法”,实际上是调用了 invoke() )。
用途:项目中途将某个类抽象为一个接口,并将原有类作为此接口的默认实现,这样可以做到源代码的兼容(对 Java 代码以及二进制仍不兼容,毕竟本质不同)。
代码来自我的项目 “MoeCraftBotNG”
其他操作符重载
一般可以重载 get() set() 来使对象能够按数组、字典一样去操作。
为对象编写 contains() 方法时(判断某个元素是否“属于”此对象),可以顺便为此方法加个 operator 关键字可以让 in 关键字支持这个对象
然而操作符重载还是慎用为妙,众所周知这个特性就是被 C++ 玩坏的,当你 java 甚至以不支持操作符重载为荣。好在 Kotlin 在这方面也比较节制。
协程
如果想让你的 suspend 函数被 Java 用户友善地调用,防止你被人砍,你可以:
用 Kotlin 编写一个类:
class Coroutines {
/**
* 获取在 Java 代码中调用 Kotlin Suspend 函数所需的最后一个参数 (Continuation)
* @param onFinished 当suspend函数执行完毕后所调用的回调。若 Throwable 不为 null 则说明执行失败。否则为执行成功
* @param dispatcher 协程执行线程的类型。可以为 Dispatchers.Default(CPU密集型) Dispatchers.Main(主线程) Dispatchers.IO(IO密集型)
*/
@JvmOverloads
fun <R> getContinuation(onFinished: BiConsumer<R?, Throwable?>, dispatcher: CoroutineDispatcher = Default): Continuation<R> {
return object : Continuation<R> {
override val context: CoroutineContext
get() = dispatcher
override fun resumeWith(result: Result<R>) {
//注意 Result 是 inline class,不可直接给出去
onFinished.accept(result.getOrNull(), result.exceptionOrNull())
}
}
}
}
kotlin suspend 函数的调用难点在于最后一个参数,这个参数是 suspend 函数自动生成的,但是在 Java 方面处理起来却十分棘手。你可以提供这样的一个类来生成最后一个参数的值。
然后在 Java 中,就可以这样调用了:
Coroutines coroutines = new Coroutines();
//假设一个 suspend fun login(username: String, password: String): RequestResult,位于 object UserUtils
UserUtils.INSTANCE.login("user", "pass", coroutines.getContinuation(
(result, throwable) -> {
//suspend fun执行结束的回调
System.out.println("Coroutines finished");
System.out.println("Result: " + result);
System.out.println("Exception: " + throwable);
}
)
);
另外,也可以使用 org.jetbrains.kotlinx:kotlinx-coroutines-jdk8,这个库可以让 suspend fun 返回 CompletableFuture<> 以便在 java 使用
fun doSomethingAsync(): CompletableFuture<List<MyClass>> =
GlobalScope.future { doSomething() } //返回 CompletableFuture 包装的 suspend fun doSomething()
内置函数
Kotlin 有很多实用的内置函数,只提几个。
run()
run() 字面意思,用于执行一个任意代码块,并返回代码块的返回值
run() 有两种,签名如下:
public inline fun <R> run(block: () -> R): R
public inline fun <T, R> T.run(block: T.() -> R): R
第一种 run() 在为构造函数委托传递参数时特别有用,例如有一个类和两个次构造函数
class ManagedJavaProperties(val inputStream: InputStream, val outputStream: OutputStream? = null) {
constructor(file: File): this(file.inputStream(), file.outputStream())
constructor(fileName: String): this(???) //需要进行处理才能委托给其他构造函数
}
第二个次构造函数中需要对 fileName 进行一些处理,此时需要 run() 登场了:
class ... {
constructor(fileName: String): this(
kotlin.run {
val file = File(fileName)
if (!file.exists()) {
file.createNewFile()
}
file
}
)
}
第二种 run() 则是将调用者当作 this 传递给 lambda,除此之外和第一种完全相同
run() 也可以用于防止代码块内变量污染当前作用域。(类似于 Java 的 { } )
抑制错误
Kotlin 的 @Suppress 注解不仅可以抑制警告,还可以抑制任何错误。具体的错误名字可以到 kotlin 编译器项目按错误提示寻找。
在普通的 Gradle Java/Kotlin 项目中使用 BuildConfig
简介
Android Studio 为其 Android 项目提供了十分方便的 BuildConfig 功能,该功能在运行编译时自动生成 BuildConfig.java 文件,其中储存了编译时的一些系统信息(如APP版本号、渠道、编译时间、编译器等),并可以用于条件编译。
所幸,有人已经仿照出了具有类似功能的 Gradle 插件。本文将说明如何使用这个插件。
使用方法
1. 添加依赖
在 build.gradle 文件中
plugins {
id 'java'
id 'de.fuerstenau.buildconfig' version '1.1.8' //添加 BuildConfig 插件
}
plugins 节应位于 import 和 buildscript 节的后面。
2. 定义项目属性
例如,对于项目 com.kenvix.moecraftbot.ng
group 'com.kenvix'
version '1.0'
def applicationName = 'MoeCraftBotNG'
def versionCode = 1
archivesBaseName = 'moecraftbot.ng'
def mainSrcDir = 'src/main/java' //项目java源代码目录
def fullPackageName = "${group}.$archivesBaseName"
def fullPackagePath = fullPackageName.replaceAll('.', '/')
def isReleaseBuild = System.getProperty("isReleaseBuild") != null //根据环境变量判断是否为正式发行版(判断是否是Release版本的构建)
3. 添加 BuildConfig 信息
/*********************************************************************/
/** Application Build Config Settings **/
/*********************************************************************/
buildConfig {
appName = project.name // sets value of NAME field
version = project.version // sets value of VERSION field,
// 'unspecified' if project.version is not set
clsName = 'BuildConfig' // sets the name of the BuildConfig class
packageName = fullPackageName // sets the package of the BuildConfig class,
// 'de.fuerstenau.buildconfig' if project.group is not set
charset = 'UTF-8' // sets charset of the generated class,
// 'UTF-8' if not set otherwise
buildConfigField 'String', 'APPLICATION_NAME', applicationName
buildConfigField 'String', 'VERSION_NAME', version as String
buildConfigField 'int', 'VERSION_CODE', versionCode as String
buildConfigField 'long', 'BUILD_UNIXTIME', System.currentTimeMillis() + 'L'
buildConfigField 'java.util.Date', 'BUILD_DATE', 'new java.util.Date(' + System.currentTimeMillis() + 'L)'
buildConfigField 'String', 'BUILD_USER', System.getProperty("user.name")
buildConfigField 'String', 'BUILD_JDK', System.getProperty("java.version")
buildConfigField 'String', 'BUILD_OS', System.getProperty("os.name")
buildConfigField 'boolean','IS_RELEASE_BUILD', isReleaseBuild as String
其中,buildConfigField 表示这是自定义字段,后面紧随的是字段类型,要用字符串书写类名。(例如 'String')
其后是字段名称 'APPLICATION_NAME'(同样用字符串),其后是内容,也必须是字符串。如果内容为 int 或 boolean 等类型,则必须强制转换。
内容部分可以书写代码,以字符串形式书写即可。
4. 让 IDE 识别代码
默认 IDE 不会识别 BuildConfig 生成的代码,为此要手动将其加入 sourceSets
// Add generated build-config directories to the main source set, so that the
// IDE doesn't complain when the app references BuildConfig classes
sourceSets.main.java {
srcDirs += new File(mainSrcDir) //项目本身源代码
srcDirs += new File(buildDir, 'gen/buildconfig/src') //BuildConfig
}
5. 生成项目
刚才我有提到“判断是否是Release版本的构建”,可以这样使用它:
例如,在打包 jar 时,可以在 gradle 命令上添加 JVM 参数 -DisReleaseBuild=true 来将 isReleaseBuild 设置为 true,让项目执行在 BuildConfig.IS_RELEASE_BUILD == true 时的代码,从而达到条件编译的效果。

项目生成后, BuildConfig 效果应该如下图所示:

配置到此结束。
我们还可以在项目启动时打印一下版本信息:
println("${BuildConfig.APPLICATION_NAME} Ver.${BuildConfig.VERSION_NAME} By Kenvix")
println("Built at ${BuildConfig.BUILD_DATE.format()} By ${BuildConfig.BUILD_USER} @ ${BuildConfig.BUILD_OS} JDK ${BuildConfig.BUILD_JDK}")
if (!BuildConfig.IS_RELEASE_BUILD)
println("Debug build")
修复国行 MIUI 打开 Google Play 始终提示 DF-DFERH-01 的问题
问题描述
自带 Google 服务框架的国行 MIUI,即使设置全局代理,打开 Google Play 仍然提示 DF-DFERH-01.
反复对 Play Store/Service 清除数据、插拔 SIM 卡均无效。在其他第三方 ROM 上 Play 正常使用。
使用 adb logcat 查看日志,捕获到下列错误:

解决
思路(过程)
- Root 手机
- 打开
adb shell - 重新挂载
/system为 RW.mount -o remount,rw /system - 强制删除
/system/etc/permissions/services.cn.google.xmlrm -f /system/etc/permissions/services.cn.google.xml - 重启手机
reboot - 对 Play Store/Service 清除缓存
上述操作将导致手机无法 OTA 升级。并且全量升级后需要重新进行上述操作
所以说这个办法并不好,为此,我制作了一个修复此问题的 Magisk 模块,下载后直接刷入即可
Magisk 模块
下载地址
https://github.com/kenvix/miui-df-dferh-01-fix/releases
随包附赠 Google Photos 原始画质无限容量解锁