在AI计算集群等场景中,系统级容器的稳定部署、GPU资源高效透传及多容器运行时兼容是核心需求,传统容器方案要么无法良好支持systemd服务管理,要么GPU透传配置复杂、需在容器内重复安装驱动,且难以兼顾Rootless Podman与Docker的二级容器运行需求。本文针对这一现状,详细阐述一套集成Nvidia GPU透传、自动驱动注入、systemd-nspawn容器管理及多二级容器运行时的完整方案,该方案已在某高校AI计算集群中稳定运行数月,可有效降低集群容器化部署的复杂度,提升资源利用率。
针对传统容器部署存在GPU透传配置繁琐、需在容器内额外安装驱动导致环境冗余、systemd支持不足、二级容器运行时兼容性差及Rootless模式适配困难等痛点,本方案核心优势在于无需在容器内安装GPU驱动,可动态扫描并挂载NVIDIA库和工具,完美支持GPU透传与CDI驱动注入,兼容Docker与Rootless Podman两种二级容器运行时,同时通过脚本实现systemd-nspawn容器的自动监控与管理,简化集群部署与运维成本。
功能特性:
- ✅ 多级容器的 NVIDIA GPU 透传支持,支持 DinD/PinD 模式
- ✅ 动态扫描 NVIDIA 库和工具,不需要在容器内安装 GPU 驱动,容器驱动自动跟随宿主机更新
- ✅ 真正的系统级容器,完美支持 systemd 服务管理,同时无Docker一级容器方案的存储冗余、可靠性差等诸多弊端。
- ✅ 支持 Docker 和 Podman 二级容器运行时,容器内可以再运行容器,支持 CDI 方式的 NVIDIA GPU 驱动注入
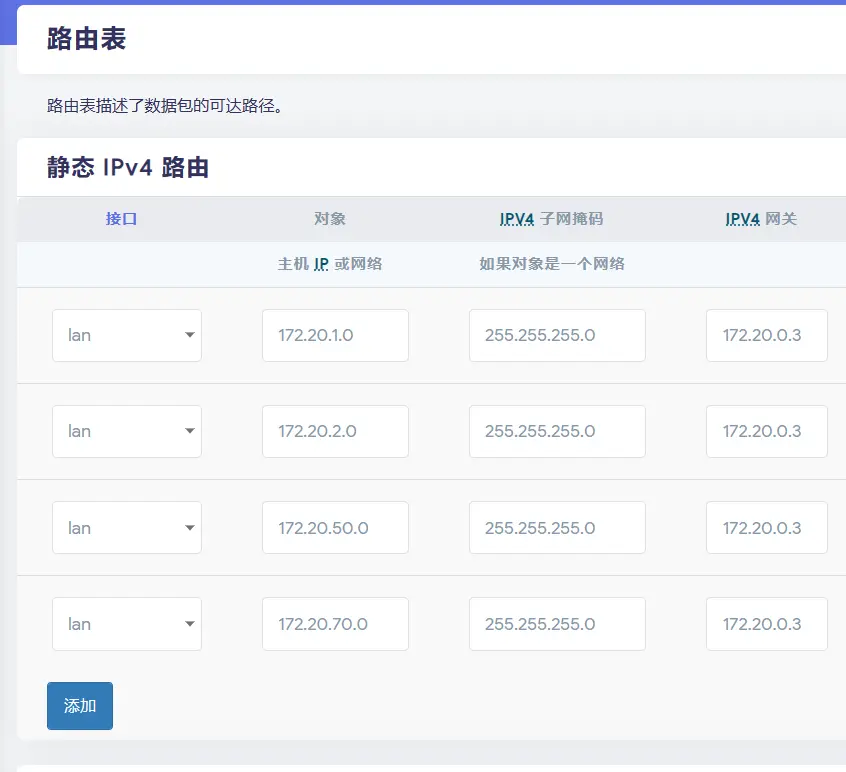
- ✅ 多节点集群支持,自动配置跨节点路由,支持宿主集群NFS。
- ✅ 支持 Rootless Podman 容器运行时,安全性风险低。
- ✅ 自动监控和管理 systemd-nspawn 容器。